Künstliche Intelligenz (KI) als Hobby / Artificial Intelligence (AI) as a Hobby
Facebook Gruppe: Künstliche Intelligenz (KI) als Hobby
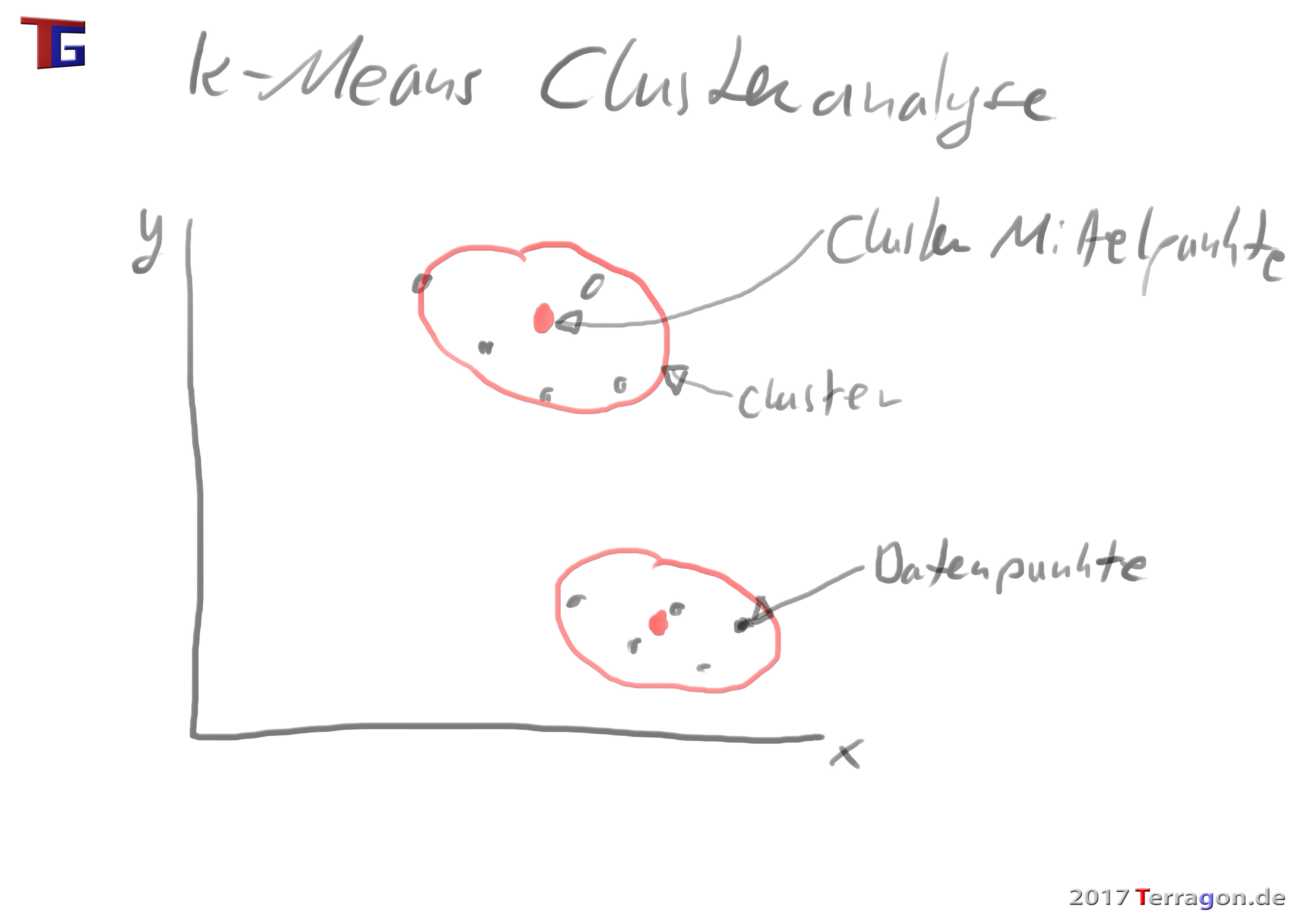
k-Means-Algorithmus für Clusteranalyse in PHP
Basierend auf dem Skript: K-Means Clustering
Angeregt durch und auf deutsch erklärt im Online-Tutorial: Machine Learning #16 - Unüberwachtes Lernen #1 - k-Means Clustering
Einleitung
Der Terragon k-Means-Algorithmus für die Clusteranalyse in PHP generiert X-Cluster von einer 2-dimensionalen Punkte-Schar, die in einem 2-dimensionalen Array übergeben wird.
Wikipedia: Ein k-Means-Algorithmus ist ein Verfahren zur Vektorquantisierung, das auch zur Clusteranalyse verwendet wird. Dabei wird aus einer Menge von ähnlichen Objekten eine vorher bekannte Anzahl von k Gruppen gebildet. Der Algorithmus ist eine der am häufigsten verwendeten Techniken zur Gruppierung von Objekten, da er schnell die Zentren der Cluster findet.
Schritt 1: Datenpunkte als Array vorgeben
Das 2-dimensionale Array besteht in unserem Beispiel aus 10 Datenpunkten, die auch grafisch in einem Koordinatnsystem dargestellt werden können.
Datenpunkte Original:
Kopieren Sie die Messdaten z.B. aus einer Tabellenkalkulation, oder tippen Sie von Hand die X Werte (links) und Y Werte (rechts) in die Felder. Jeder Wert muss in eine neue Zeile geschrieben werden (und die Zeilen-Anzahl von X und Y muss natürlich gleich sein).
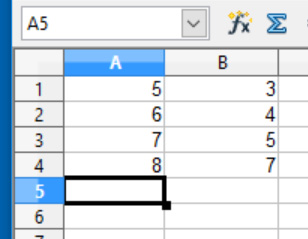
Diese Daten wurden erkannt:
Array
(
[0] => Array
(
[0] => 1
[1] => 2
)
[1] => Array
(
[0] => 2
[1] => 3
)
[2] => Array
(
[0] => 3
[1] => 4
)
[3] => Array
(
[0] => 6
[1] => 6
)
[4] => Array
(
[0] => 9
[1] => 5
)
[5] => Array
(
[0] => 8
[1] => 8
)
[6] => Array
(
[0] => 7
[1] => 9
)
[7] => Array
(
[0] => 5
[1] => 3
)
[8] => Array
(
[0] => 6
[1] => 2
)
[9] => Array
(
[0] => 4
[1] => 5
)
)
Schritt 2: Datenpunkte Normalisieren
Je nachdem, wie die Punkte vorgegeben wurden, müssen sie vor der Verarbeitung normalisiert werden, also in einen Wertebereich zwischen 0 und 1 skaliert werden.
Datenpunkte Normalisiert:
Array
(
[0] => Array
(
[0] => 0.44721359549996
[1] => 0.89442719099992
)
[1] => Array
(
[0] => 0.55470019622523
[1] => 0.83205029433784
)
[2] => Array
(
[0] => 0.6
[1] => 0.8
)
[3] => Array
(
[0] => 0.70710678118655
[1] => 0.70710678118655
)
[4] => Array
(
[0] => 0.87415727612154
[1] => 0.48564293117863
)
[5] => Array
(
[0] => 0.70710678118655
[1] => 0.70710678118655
)
[6] => Array
(
[0] => 0.61394061351492
[1] => 0.78935221737633
)
[7] => Array
(
[0] => 0.85749292571254
[1] => 0.51449575542753
)
[8] => Array
(
[0] => 0.94868329805051
[1] => 0.31622776601684
)
[9] => Array
(
[0] => 0.62469504755442
[1] => 0.78086880944303
)
)
Schritt 3: k-Means Clustering durchführen
Jetzt wird die Clusteranalyse per Iteration durchgeführt.
In dem Array werden die Cluster-Mittelpunkte unter [centroids] wiedergegeben.
Darunter werden dann die Cluster-Arrays mit den Datenpunkten ausgegeben. Die [Nummer] vor den Datenpunkten im Array entspricht der [Nummer] des Cluster-Mittelpunktes darüber mit der gleichen Nummer.
Ergebnis Cluster:
Array
(
[centroids] => Array
(
[0] => Array
(
[0] => 0.06941056083938
[1] => 0.086763201049226
)
[1] => Array
(
[0] => 0.94868329805051
[1] => 0.31622776601684
)
[2] => Array
(
[0] => 0.81373347120674
[1] => 0.5812381937191
)
)
[2] => Array
(
[0] => 0.44721359549996,0.89442719099992
[1] => 0.55470019622523,0.83205029433784
[2] => 0.6,0.8
[3] => 0.70710678118655,0.70710678118655
[4] => 0.87415727612154,0.48564293117863
[5] => 0.70710678118655,0.70710678118655
[6] => 0.61394061351492,0.78935221737633
[7] => 0.85749292571254,0.51449575542753
[8] => 0.62469504755442,0.78086880944303
)
[1] => Array
(
[0] => 0.94868329805051,0.31622776601684
)
)
Hinweise:
Die Ergebnisse sind die normalisierten Koordinaten! Es können also leider nicht direkt die originalen Punkte abgelesen werden!